
Trong nghiên cứu khoa học và phân tích dữ liệu, one way anova thường được ví như một “chìa khóa” giúp người làm thống kê kiểm tra sự khác biệt giữa nhiều nhóm một cách rõ ràng và có căn cứ. Đây không chỉ là một kỹ thuật tính toán, mà còn là cách tiếp cận giúp nhà nghiên cứu tránh suy luận cảm tính khi so sánh các nhóm dữ liệu. Nhờ tính ứng dụng rộng, phương pháp này xuất hiện phổ biến trong kinh tế, y học, tâm lý học, giáo dục và cả các bài toán quản trị, nơi yêu cầu ra quyết định dựa trên bằng chứng.
Bài viết này đi theo lộ trình từ khái niệm đến thực hành: bạn sẽ hiểu one way anova là gì, khi nào nên dùng, các giả định cần kiểm tra, sự khác nhau giữa các kiểm định chính, rồi đến hướng dẫn thao tác trong SPSS và cách đọc kết quả. Nội dung phù hợp cho người mới bắt đầu lẫn những ai muốn hệ thống hóa kỹ năng phân tích số liệu một cách bài bản.
Định nghĩa One Way ANOVA
Nắm chắc định nghĩa là bước đầu để dùng đúng và giải thích đúng. Dù one way anova nghe có vẻ đơn giản, phương pháp này chứa nhiều điểm quan trọng liên quan đến cấu trúc dữ liệu, giả định thống kê và cách diễn giải kết quả. Khi hiểu đúng nền tảng, bạn sẽ dễ dàng mở rộng sang các phân tích nâng cao hơn về sau.
Khái niệm cơ bản
one way anova là phương pháp thống kê dùng để so sánh trung bình của từ ba nhóm độc lập trở lên, nhằm xác định xem các nhóm đó có khác nhau một cách có ý nghĩa thống kê hay không. Cách tiếp cận dựa trên giả thuyết không (H0) rằng trung bình của các nhóm bằng nhau; nếu dữ liệu cho thấy bằng chứng đủ mạnh để bác bỏ H0, ta kết luận rằng tồn tại ít nhất một cặp nhóm có trung bình khác biệt.
Phương pháp này thường được áp dụng khi biến phụ thuộc là định lượng (điểm số, doanh số, mức độ hài lòng…) và biến độc lập là biến phân nhóm (khu vực, giới tính, loại sản phẩm, nhóm điều trị…). Điểm mạnh của one way anova nằm ở khả năng so sánh nhiều nhóm trong một lần phân tích, giúp tiết kiệm thời gian và tránh sai lầm khi thực hiện quá nhiều phép so sánh riêng lẻ.
Các yếu tố chính trong One Way ANOVA
Để phân tích đúng, bạn cần xác định rõ:
- Biến độc lập: biến dùng để phân nhóm (ví dụ: trình độ học vấn, vùng miền, nhóm điều trị).
- Biến phụ thuộc: biến định lượng cần so sánh trung bình giữa các nhóm (ví dụ: điểm, năng suất, mức độ hài lòng).
- Các giả định quan trọng: mẫu độc lập; phân phối gần chuẩn trong từng nhóm; phương sai giữa các nhóm tương đối đồng nhất.
Khi các điều kiện này được kiểm tra và thỏa mãn, kết quả one way anova sẽ đáng tin hơn và dễ diễn giải hơn.
So sánh với các phương pháp khác
| Phương pháp | Số nhóm so sánh | Dữ liệu phù hợp | Ưu điểm | Hạn chế |
| T-test độc lập | 2 | Gần chuẩn, phương sai tương đương | Dễ dùng, nhanh | Không phù hợp khi > 2 nhóm |
| one way anova | ≥ 3 | Gần chuẩn, phương sai tương đối đồng nhất | So sánh nhiều nhóm cùng lúc | Cần kiểm tra giả định |
| Kruskal-Wallis | ≥ 3 | Không yêu cầu chuẩn, có thể dùng cho dữ liệu lệch/ordinal | Linh hoạt khi vi phạm giả định | Ít nhạy hơn, diễn giải kém trực quan |
Ứng dụng trong nghiên cứu thống kê
Trong thực tế, one way anova xuất hiện ở nhiều bối cảnh:
- Giáo dục: so sánh điểm trung bình giữa nhiều lớp hoặc nhiều phương pháp dạy.
- Y học: đánh giá hiệu quả điều trị giữa các nhóm bệnh nhân khác nhau.
- Kinh doanh: so sánh mức độ hài lòng theo phân khúc khách hàng hoặc chi nhánh.
- Xã hội học: phân tích thái độ/hành vi giữa các nhóm dân cư.
Nhờ vậy, nhà nghiên cứu vừa tiết kiệm công sức, vừa đảm bảo kết luận dựa trên kiểm định khách quan.
Mục đích của One Way ANOVA
Hiểu mục đích giúp bạn đặt đúng câu hỏi nghiên cứu và chọn đúng cách diễn giải. Trong nhiều dự án, người phân tích không chỉ cần biết “có khác nhau không”, mà còn cần hiểu sự khác nhau đó nói lên điều gì trong bối cảnh thực tiễn.
So sánh giá trị trung bình giữa các nhóm
Mục tiêu trung tâm của one way anova là kiểm tra xem trung bình của các nhóm có thực sự khác nhau hay chỉ khác do ngẫu nhiên. Ví dụ: khảo sát mức độ hài lòng của khách hàng giữa các chi nhánh, bạn có thể dùng phân tích này để xem chi nhánh nào đang có mức hài lòng thấp hơn rõ rệt, từ đó ưu tiên cải thiện dịch vụ.
Xác định tác động của biến độc lập lên biến phụ thuộc
Phương pháp cũng giúp bạn đánh giá xem “yếu tố phân nhóm” có tác động đáng kể đến kết quả hay không. Chẳng hạn, khi nghiên cứu năng suất theo độ tuổi, one way anova giúp kiểm tra liệu khác biệt về năng suất giữa các nhóm tuổi có đủ mạnh để kết luận rằng độ tuổi liên quan đến năng suất trong dữ liệu hay không.
Ứng dụng thực tế trong các bài nghiên cứu
Từ luận văn đại học đến báo cáo doanh nghiệp, kỹ thuật này thường được dùng để đánh giá sự khác biệt giữa các chiến dịch quảng cáo, các chương trình đào tạo, hoặc các nhóm khách hàng. Khi kết quả cho thấy khác biệt có ý nghĩa, tổ chức có thể điều chỉnh chiến lược dựa trên bằng chứng thay vì cảm giác.
Hai loại kiểm định chính của One Way ANOVA

Trong thực hành, bạn thường gặp hai bước: kiểm định tổng thể để xem có khác biệt hay không, và kiểm định hậu nghiệm để chỉ rõ nhóm nào khác nhóm nào. Nắm được vai trò từng bước giúp bạn tránh kết luận sai hoặc kết luận thiếu.
Kiểm định F-test
F-test là bước “gác cổng” của one way anova. Nó kiểm tra giả thuyết rằng tất cả nhóm có cùng trung bình. Về bản chất, F được hình thành từ tỷ lệ giữa phương sai giữa các nhóm và phương sai trong nhóm. Nếu tỷ lệ này đủ lớn và p-value nhỏ hơn mức ý nghĩa (thường là 0.05), ta kết luận có khác biệt trung bình giữa ít nhất hai nhóm.
Một cách hình dung đơn giản: nếu các nhóm tách biệt rõ ràng (trung bình nhóm cách xa nhau), phương sai giữa nhóm lớn; khi đó F có xu hướng lớn hơn và dễ cho kết luận có khác biệt.
Kiểm định hậu nghiệm Tukey’s HSD
Khi F-test cho thấy có khác biệt, bạn cần biết khác ở đâu. Tukey’s HSD là một kiểm định hậu nghiệm phổ biến dùng để so sánh từng cặp nhóm, giúp xác định cặp nào khác biệt đáng kể. Điểm mạnh của Tukey là kiểm soát tốt nguy cơ “báo động giả” khi so sánh nhiều cặp cùng lúc.
Trong bảng kết quả, bạn chỉ cần xem p-value của từng cặp: nếu nhỏ hơn 0.05, có thể nói trung bình hai nhóm đó khác nhau một cách có ý nghĩa thống kê.
So sánh giữa F-test và Tukey’s HSD
F-test trả lời câu hỏi: “Có khác biệt tổng thể hay không?”. Tukey trả lời câu hỏi: “Nhóm nào khác nhóm nào?”. Vì vậy, quy trình hợp lý là chạy F-test trước, rồi mới dùng hậu nghiệm để đào sâu vào các cặp nhóm.
Các bước thực hiện chung cho hai loại kiểm định
Dù bạn dùng F-test hay hậu nghiệm, quy trình cốt lõi vẫn gồm: chuẩn hóa dữ liệu đúng dạng, chọn đúng biến, kiểm tra giả định (đặc biệt là đồng nhất phương sai), chạy phân tích và diễn giải kết quả theo p-value cùng các chỉ số liên quan. Nếu cần tài liệu hướng dẫn thao tác SPSS theo từng bước, bạn có thể tham khảo thêm tại chayspss.
Thực hành kiểm định One Way ANOVA trong SPSS
Lý thuyết chỉ thực sự có giá trị khi bạn áp dụng được vào dữ liệu thực tế. Dưới đây là quy trình thao tác cơ bản trong SPSS, kèm cách đọc các bảng kết quả quan trọng để đưa ra kết luận chính xác.
Các bước thực hiện trong SPSS
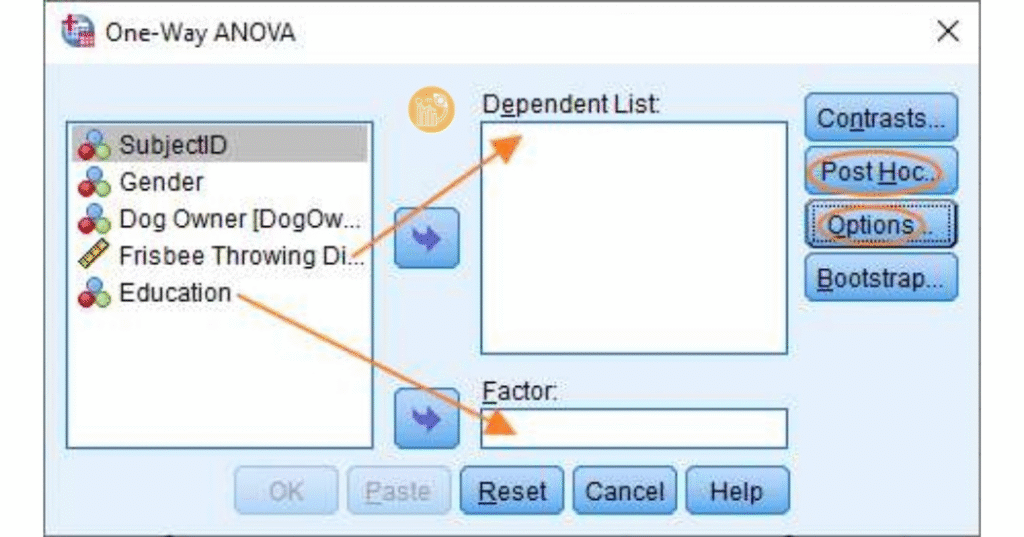
Ví dụ: kiểm tra xem trình độ học vấn (trung học, cao học, sau đại học) có liên quan đến khoảng cách ném đĩa hay không.
- Biến độc lập: trình độ học vấn
- Biến phụ thuộc: khoảng cách ném đĩa
Mở SPSS, vào Analyze > Compare Means > One-Way ANOVA.
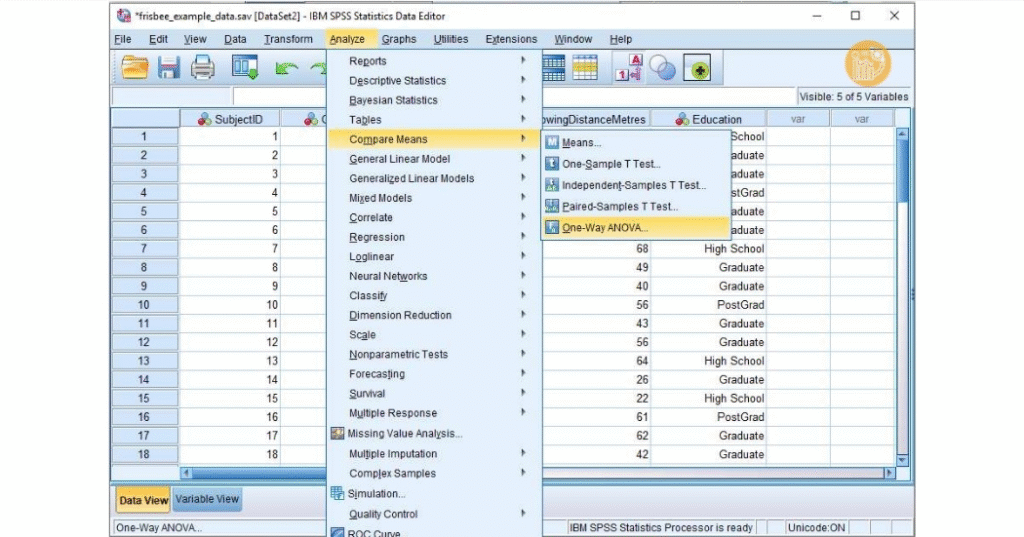
Đưa biến nhóm vào Factor, biến đo lường vào Dependent List. Chọn Post Hoc.
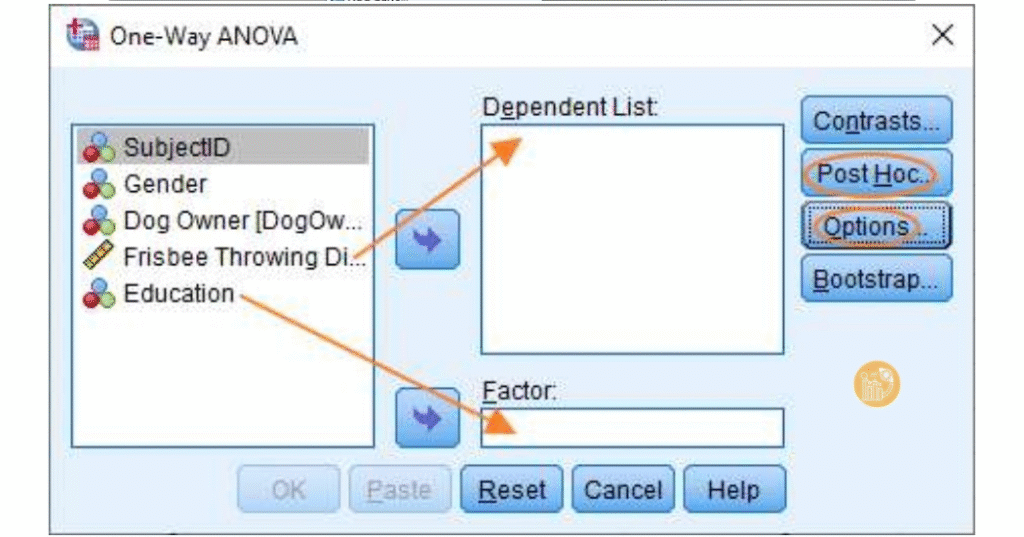
Trong Post Hoc, chọn Tukey và giữ mức ý nghĩa 0.05, bấm Continue.
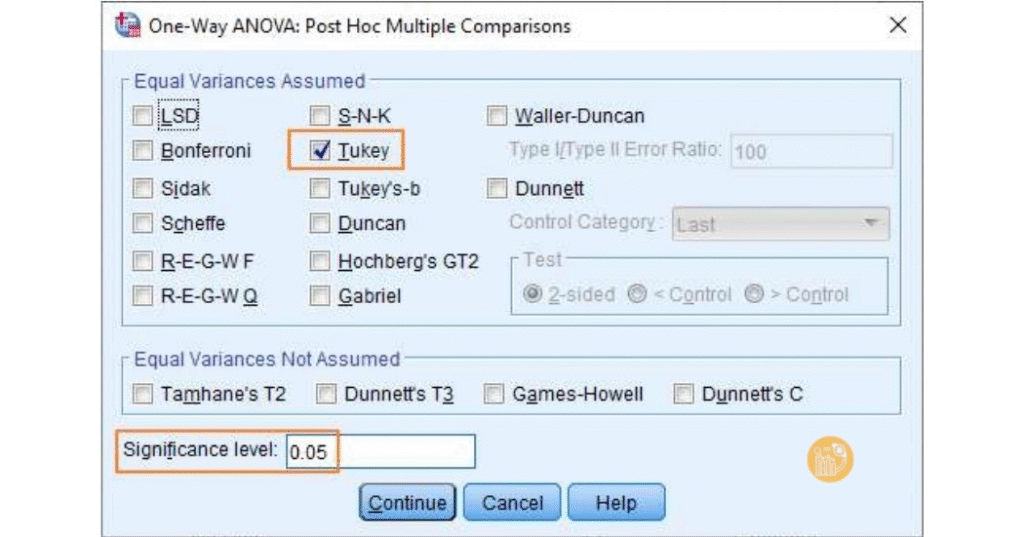
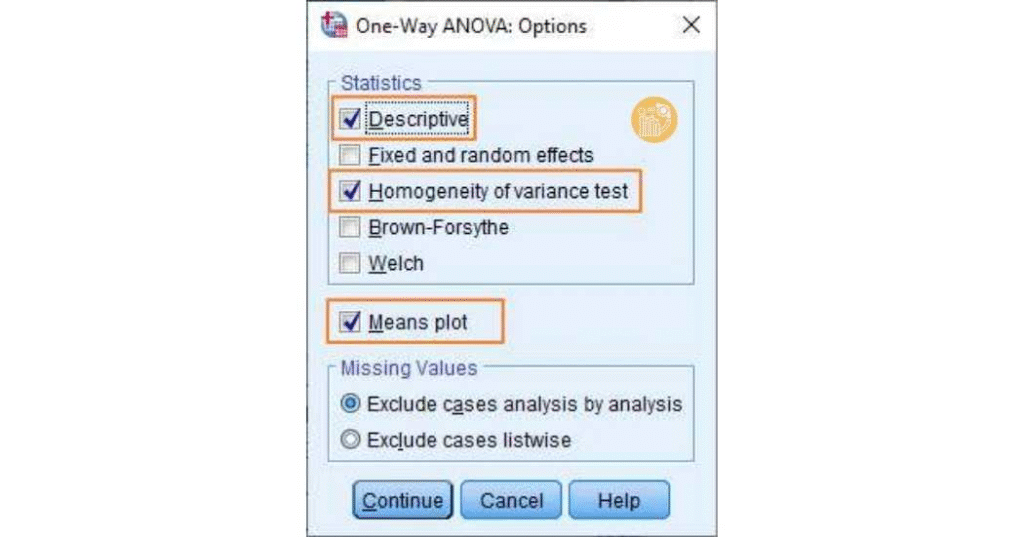
Chọn Options.
Tích Descriptive, Homogeneity of variance test, Mean plot rồi bấm Continue, sau đó OK.
Kết quả sẽ bao gồm thống kê mô tả, kiểm định Levene, bảng ANOVA và bảng hậu nghiệm Tukey (nếu cần).
Cách đọc và phân tích kết quả
- ANOVA Table: xem F và p-value. Nếu p < 0.05, kết luận có khác biệt trung bình giữa ít nhất hai nhóm.
- Levene’s Test: nếu p > 0.05, giả định phương sai đồng nhất tương đối ổn; nếu p ≤ 0.05, cân nhắc phương án thay thế hoặc điều chỉnh.
- Descriptives: xem trung bình, độ lệch chuẩn, số quan sát từng nhóm để hình dung chênh lệch.
- Post Hoc (Tukey): xác định cặp nhóm nào khác biệt bằng p-value theo từng cặp.
- Mean Plot: quan sát trực quan xu hướng trung bình giữa các nhóm.
Lưu ý khi chuẩn bị dữ liệu
Để kết quả đáng tin, bạn nên làm sạch dữ liệu trước khi chạy: kiểm tra thiếu dữ liệu, giá trị ngoại lai, mã hóa nhóm đúng, và đảm bảo biến phụ thuộc là định lượng. Nếu dữ liệu lệch quá mạnh hoặc phương sai không đồng nhất, bạn có thể cân nhắc biến đổi dữ liệu hoặc dùng phương pháp phi tham số phù hợp.
Mở rộng ứng dụng với các phần mềm khác
Ngoài SPSS, one way anova cũng có thể thực hiện trong R, STATA, SAS hoặc Python. Mỗi công cụ có cú pháp riêng nhưng logic thống kê tương tự. Việc biết thêm nhiều công cụ sẽ giúp bạn linh hoạt khi làm dự án, đặc biệt trong môi trường phân tích dữ liệu lớn hoặc yêu cầu tự động hóa.
Kết luận
one way anova là một kỹ thuật mạnh để kiểm tra sự khác biệt trung bình giữa nhiều nhóm, hỗ trợ nhà nghiên cứu đưa ra kết luận khách quan và có cơ sở thống kê. Khi bạn nắm rõ khái niệm, giả định, vai trò của F-test và Tukey, cùng cách thao tác và đọc bảng kết quả trong SPSS, việc phân tích sẽ trở nên mạch lạc và thuyết phục hơn. Đây là một kỹ năng đáng đầu tư nếu bạn muốn nâng cao chất lượng luận văn, báo cáo nghiên cứu hoặc các quyết định dựa trên dữ liệu trong công việc.
Khám phá Dịch vụ SPSS tại: Dịch vụ chạy SPSS | Uy tín & Hiệu quả
Khám phá Dịch vụ AMOS tại: Dịch vụ chạy AMOS | Uy tín & Hiệu quả
Khám phá Dịch vụ STATA/EVIEWS tại: Dịch vụ chạy STATA/EVIEWS | Uy tín & Hiệu quả
Khám phá Dịch vụ SMARTPLS tại: Dịch vụ chạy SMARTPLS | Uy tín & Hiệu quả