
Trong nghiên cứu khoa học xã hội và các dự án phân tích dữ liệu khảo sát, phân tích nhân tố khám phá (EFA) thường được dùng để rút gọn biến và nhận diện cấu trúc yếu tố ẩn trong tập dữ liệu nhiều biến quan sát. Tuy nhiên, khi triển khai EFA, người làm nghiên cứu rất hay gặp tình huống ma trận xoay cho ra kết quả “nhảy lung tung”, nhóm biến không gom lại như kỳ vọng, thậm chí thuật toán xoay không hội tụ. Đây là nhóm các lỗi thường gặp khi chạy efa vì nó khiến mô hình khó diễn giải, làm giảm độ tin cậy của thang đo và kéo theo nhiều vấn đề ở các bước sau như CFA/SEM.
Bài viết này hệ thống lại dấu hiệu nhận biết, phân biệt trường hợp “bình thường” và trường hợp “cần xử lý”, đồng thời đưa ra hướng khắc phục theo quy trình thực tế. Nội dung phù hợp cho người chạy dữ liệu bằng phân tích EFA trong SPSS, đặc biệt khi bạn đang xây thang đo dựa trên lý thuyết và muốn ma trận xoay phản ánh được cấu trúc đó. Nếu bạn cần thêm ví dụ thao tác hoặc checklist kiểm tra dữ liệu khảo sát, có thể tham khảo tại chayspss.
1. Như thế nào gọi là ma trận xoay xáo trộn, không hội tụ?
Trước khi “sửa”, cần hiểu đúng: ma trận xoay trông lộn xộn không phải lúc nào cũng là sai. EFA vốn được thiết kế để khám phá cấu trúc tiềm ẩn, nên đôi khi việc biến quan sát tải lên nhân tố khác với dự kiến lại là tín hiệu cho một cấu trúc mới trong dữ liệu. Vấn đề chỉ trở nên nghiêm trọng khi mức xáo trộn khiến các biến không còn hội tụ thành nhóm rõ ràng, tải chéo nhiều, hoặc phần mềm báo xoay không hội tụ (iteration không đạt, không tìm được nghiệm ổn định). Đây là dạng lỗi trong phân tích nhân tố khám phá mà bạn cần can thiệp.
Một tình huống “cần xử lý” thường xuất hiện khi bạn đã có khung thang đo từ lý thuyết. Ví dụ, mô hình dự kiến có các nhân tố A, B, C; trong đó A được đo bằng A1, A2, A3; B đo bằng B1, B2, B3; C đo bằng C1, C2, C3. Nhưng khi chạy EFA, các biến A1, A2 lại tải mạnh sang nhân tố B; hoặc A1 vừa tải lên A vừa tải lên C; hoặc xuất hiện một nhân tố mới gồm biến “trộn” từ nhiều nhóm khác nhau. Khi cấu trúc lý thuyết bị phá vỡ và các nhóm biến không còn phân tách, ma trận xoay bị xem là xáo trộn.
Ví dụ về dạng ma trận xoay xáo trộn
- Giữ đúng số nhân tố theo lý thuyết: số nhân tố không đổi nhưng các biến quan sát bị “đổi nhà”, tải chéo nhiều, khó đặt tên.
- Giảm số nhân tố so với lý thuyết: ví dụ dự kiến 4 nhân tố nhưng kết quả gom lại còn 3, khiến một số khái niệm bị dính vào nhau.
- Tăng số nhân tố so với lý thuyết: ví dụ từ 4 nhân tố tách thành 6–8 nhân tố, thường đi kèm nhiều biến yếu hoặc cấu trúc không ổn định.
Ngược lại, nếu bạn mới chỉ có một danh sách biến quan sát và chưa khẳng định cấu trúc nhân tố từ trước, EFA có thể được dùng như bước khám phá thuần túy. Lúc đó, việc ma trận xoay “khác kỳ vọng” không nhất thiết là lỗi; nhiệm vụ chính là xem nhóm biến nào hội tụ, đặt tên nhân tố phù hợp và tiếp tục các bước kiểm định sau.
2. Ma trận xoay lộn xộn là xấu hay bình thường?
Trong nhiều nghiên cứu, việc xuất hiện nhân tố mới hoặc số nhân tố thay đổi so với mô hình ban đầu có thể là một phát hiện đáng giá. Nó gợi ý rằng cấu trúc lý thuyết có thể chưa phù hợp hoàn toàn với bối cảnh mẫu nghiên cứu, hoặc thang đo cần điều chỉnh để phản ánh thực tế tốt hơn. Vì vậy, không nên “mặc định” coi mọi xáo trộn là thất bại.
Tuy nhiên, nếu sự xáo trộn xảy ra trên diện rộng (quá nhiều tải chéo, nhân tố mới sinh ra hàng loạt, biến quan sát không tạo cụm rõ ràng) hoặc thuật toán xoay liên tục không hội tụ, đây là dấu hiệu dữ liệu/biến quan sát có vấn đề. Khi đó, kết quả EFA trở nên khó diễn giải, độ ổn định thấp và ảnh hưởng dây chuyền đến các phân tích tiếp theo. Đây chính là nhóm các lỗi thường gặp khi chạy efa mà người làm dữ liệu cần xử lý theo quy trình.
3. Cách xử lý ma trận xoay xáo trộn, không hội tụ – các lỗi thường gặp khi chạy efa

3.1 Xác định phương thức triển khai EFA chung hay riêng
Một nguyên nhân hay gặp là cách “gom biến” để chạy EFA. Có bộ dữ liệu cho kết quả tốt khi chạy EFA riêng theo từng nhóm khái niệm, nhưng lại kém khi chạy chung tất cả biến. Tình huống này thường xảy ra khi bạn đưa cả biến độc lập và biến phụ thuộc vào cùng một lần EFA, đặc biệt khi các nhóm biến có quan hệ chặt chẽ. Khi biến độc lập giải thích mạnh cho biến phụ thuộc, cấu trúc có thể bị kéo dính, khiến nhân tố không tách rõ và làm ma trận xoay rối hoặc không hội tụ.
Vì vậy, trước khi kết luận do “dữ liệu xấu”, hãy thử chiến lược phân tích phù hợp: chạy EFA theo từng thang đo/nhóm biến trước, sau đó mới cân nhắc chạy chung nếu cần. Đây là một bước khắc phục lỗi EFA rất thực dụng khi làm việc với dữ liệu khảo sát.
3.2 Nhận diện dạng xáo trộn có thể cải thiện được
Không phải ma trận xoay nào cũng “cứu” được. Bạn nên đánh giá khả năng cải thiện dựa trên mức độ lệch so với mô hình lý thuyết. Một ma trận xoay thường được xem là có thể cải thiện nếu:
- Số nhân tố mới tăng/giảm không quá nhiều so với số nhân tố dự kiến.
- Số nhân tố vẫn giữ được cụm biến theo lý thuyết nhiều hơn số nhân tố bị phá vỡ.
- Cấu trúc bị lệch nhưng chưa đến mức “trộn toàn diện”, vẫn còn ranh giới nhóm biến tương đối rõ.

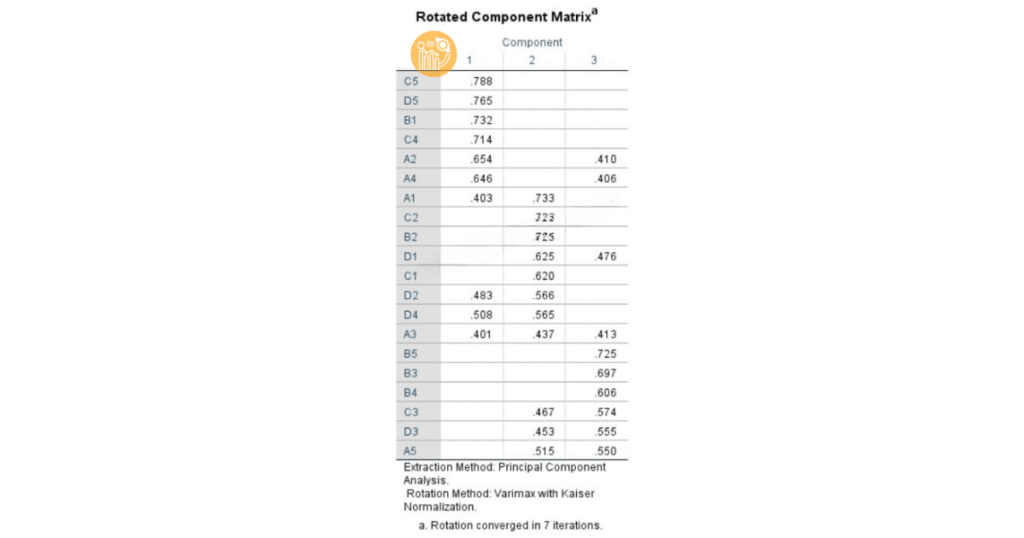
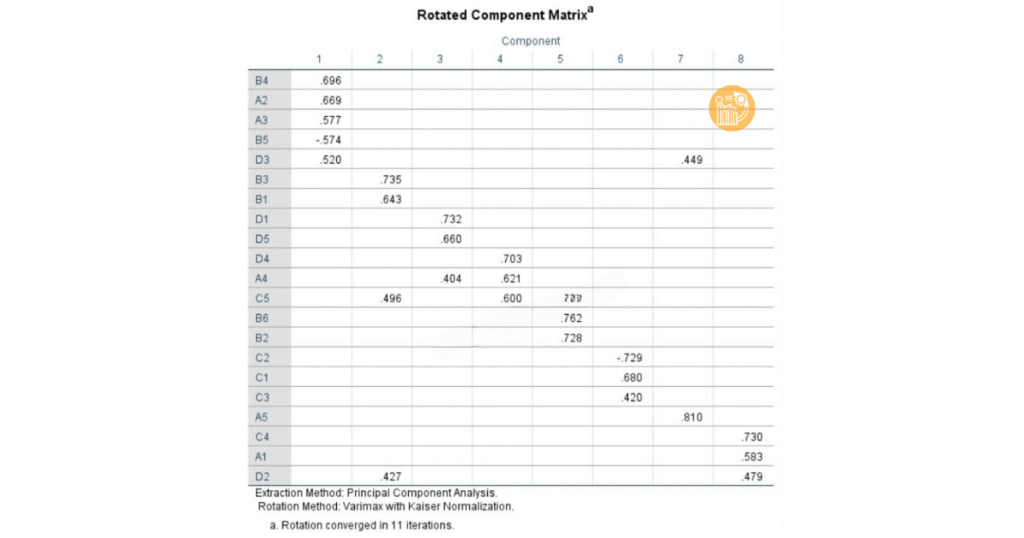
Nếu dữ liệu đầu vào quá kém (nhiều biến yếu, nhiều phiếu không hợp tác, biến đo không rõ nghĩa, thang đo thiết kế thiếu chặt), đôi khi tối ưu trong phần mềm không giải quyết được. Khi đó, phương án đúng là chỉnh bảng hỏi và thu thập lại dữ liệu để đảm bảo chất lượng trước khi tiếp tục EFA.
3.3 Quy trình khắc phục ma trận xoay xáo trộn, không hội tụ
Khi đã xác định vấn đề thuộc nhóm có thể xử lý, bạn có thể áp dụng lần lượt các bước sau. Đây là checklist khắc phục lỗi EFA thường dùng trong phân tích EFA trong SPSS:
- Kiểm tra độ tin cậy thang đo bằng Cronbach’s Alpha: loại biến rác (tương quan biến-tổng thấp, làm Alpha tăng khi loại bỏ) trước khi chạy EFA.
- Thống kê mô tả và kiểm tra trung bình: rà các biến có giá trị bất thường, thiếu dữ liệu, hoặc phân phối quá lệch gây nhiễu xoay.
- Rà soát phiếu khảo sát không hợp tác: loại các phiếu chọn một cột quá nhiều, trả lời theo mẫu lặp, hoặc có dấu hiệu làm cho có.
- Kiểm tra logic thông tin cá nhân/nền: loại các trường hợp “phi thực tế” (tuổi/thu nhập/kinh nghiệm không hợp lý) nếu bạn xác định đó là dữ liệu sai.
- Loại biến quan sát yếu trong EFA: biến có tải nhân tố thấp, tải chéo cao, hoặc không hội tụ ổn định nên được cân nhắc loại để làm rõ cấu trúc.
Sau khi làm sạch và loại biến, bạn chạy lại EFA. Những nhân tố vẫn giữ được cấu trúc theo lý thuyết có thể duy trì. Với các nhân tố mới hình thành, bạn cần xem nội dung các biến hội tụ để đặt tên lại cho phù hợp, đồng thời ghi chú rõ trong báo cáo (vì đây là thay đổi so với khung lý thuyết ban đầu). Đây là cách xử lý nhất quán nhằm giảm lỗi trong phân tích nhân tố khám phá và tăng khả năng diễn giải.
Kết luận chung về việc khắc phục ma trận xoay EFA xáo trộn
- Ma trận xoay xáo trộn không luôn là “xấu”; đôi khi nó phản ánh cấu trúc mới đáng chú ý trong dữ liệu.
- Dữ liệu chất lượng thấp là nguyên nhân phổ biến khiến xoay không hội tụ; nếu không cải thiện được, thu thập lại dữ liệu thường là lựa chọn đúng.
- Kiểm tra độ tin cậy thang đo, loại biến yếu, sàng lọc phiếu không hợp tác và điều chỉnh bảng hỏi là các bước quan trọng để tối ưu EFA.
Hy vọng hướng dẫn này giúp bạn nhận diện chính xác các lỗi thường gặp khi chạy efa và có quy trình xử lý rõ ràng để nâng chất lượng kết quả. Nếu bạn đang thao tác trên SPSS và cần thêm tài liệu hướng dẫn theo tình huống, có thể tham khảo thêm tại chayspss.
Khám phá Dịch vụ SPSS tại: Dịch vụ chạy SPSS | Uy tín & Hiệu quả
Khám phá Dịch vụ AMOS tại: Dịch vụ chạy AMOS | Uy tín & Hiệu quả
Khám phá Dịch vụ STATA/EVIEWS tại: Dịch vụ chạy STATA/EVIEWS | Uy tín & Hiệu quả
Khám phá Dịch vụ SMARTPLS tại: Dịch vụ chạy SMARTPLS | Uy tín & Hiệu quả